Fraunhofer-Institut für Techno- und Wirtschaftsmathematik ITWM
Fraunhofer-Institut für Techno- und Wirtschaftsmathematik ITWM
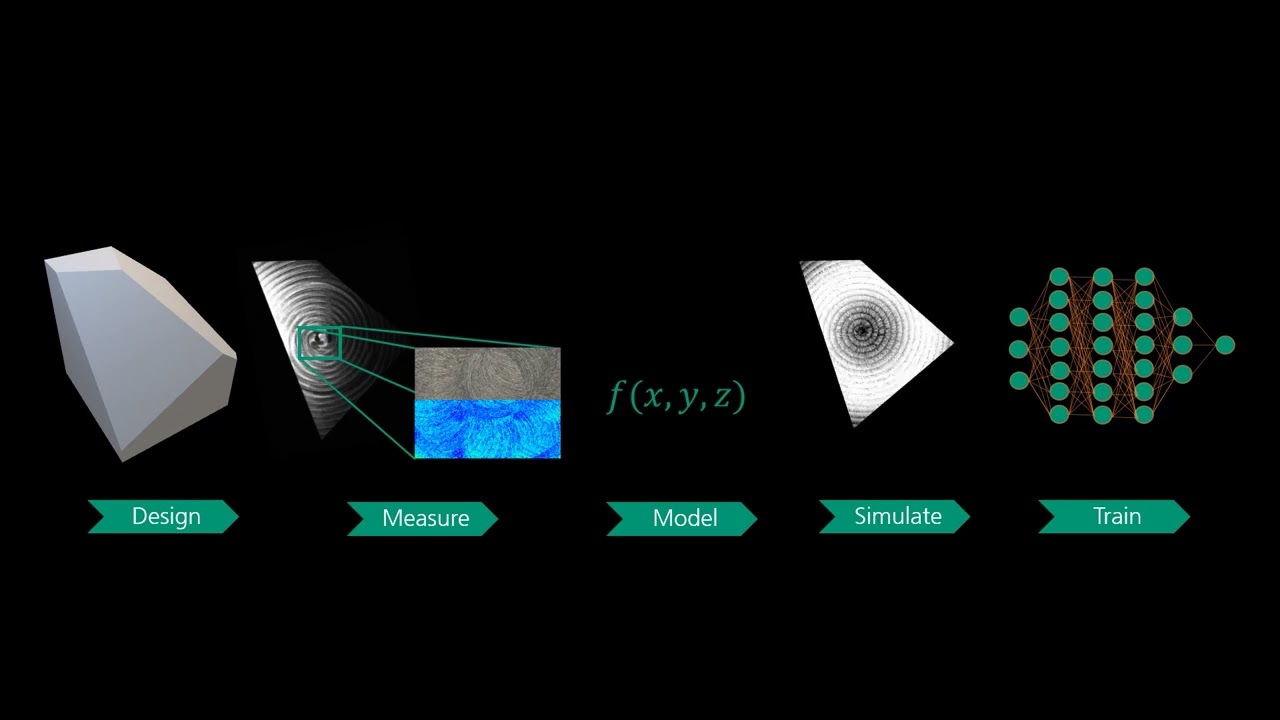
Im Projekt »SynosIs« entwickeln wir gemeinsam mit unseren Forschungspartner:innen ein Inspektionssytem, das auf Künstlicher Intelligenz (KI) beruht und Defekte auf Oberflächen schnell und automatisiert erkennt. Das Projekt wird vom Bundesministerium für Bildung und Forschung (BMBF) gefördert.
Bildverarbeitungssysteme zur Qualitätskontrolle in der Produktion lösen zunehmend komplexere Aufgaben und müssen aufgrund kurzer Entwicklungszyklen immer schneller auf neue Produkte und Fehlerbilder reagieren. Typische Prüfaufgaben sind die Detektion von Oberflächenfehlern und Abweichungen von der Sollgeometrie. Künstliche Intelligenz (KI) kommt in Bilderkennung, -verarbeitung und -verstehen zwar zum Teil erfolgreich zum Einsatz. Das Training eines robusten, automatischen, KI-basierten Inspektionssystems erfordert jedoch eine große Menge manuell annotierter Bilddaten, die insbesondere für alle Fehlertypen repräsentativ sein müssen.