Representation Learning (RL)
Representation Learning (RL) umfasst eine Sammlung von Methoden, die aus einem Inputvektor automatisch Repräsentationen generiert, die ein anschließendes überwachtes Lernen wie z. B. Klassifikation ermöglichen. »Deep-Learning« Methoden sind RL-Methoden mit multiplen Ebenen, jede Ebene transformiert die vorherige Repräsentation in einen abstrakteren Level angefangen mit den Rohdaten.
Mit anderen Worten: Jede RL-Ebene eines Deep Neural Network versucht ausgehend von der Gültigkeit der Mannigfaltigkeitshypothese (Komplexe Datenmannigfaltigkeiten sind an sich niedrigdimensional) Merkmale zu generieren, die dann z. B. einfacher zu klassifizieren sind. Das heißt, die Variationen entlang der Mannigfaltigkeiten werden detektiert und die orthogonalen Variationen der zur Mannigfaltigkeit tangierenden Räume werden ignoriert. Weiterhin wurde von Bengio (2013) gezeigt, dass die RL-Methode »Auto-encoder« komplexe Datenmannigfaltigkeiten in jedem Layer des Deep Neural Networks entflechtet.
Ansätze des RL
Zurzeit existieren zwei parallel verfolgte Ansätze für RL:
- der erste hat seinen Ursprung in probabilistischen graphischen Modellen; Hauptrepräsentanten sind »Restricted Boltzmann Machines (RBM)«,
- der andere in neuronalen Netzen, Hauptrepräsentanten sind die sogenannten Auto-Encoder.
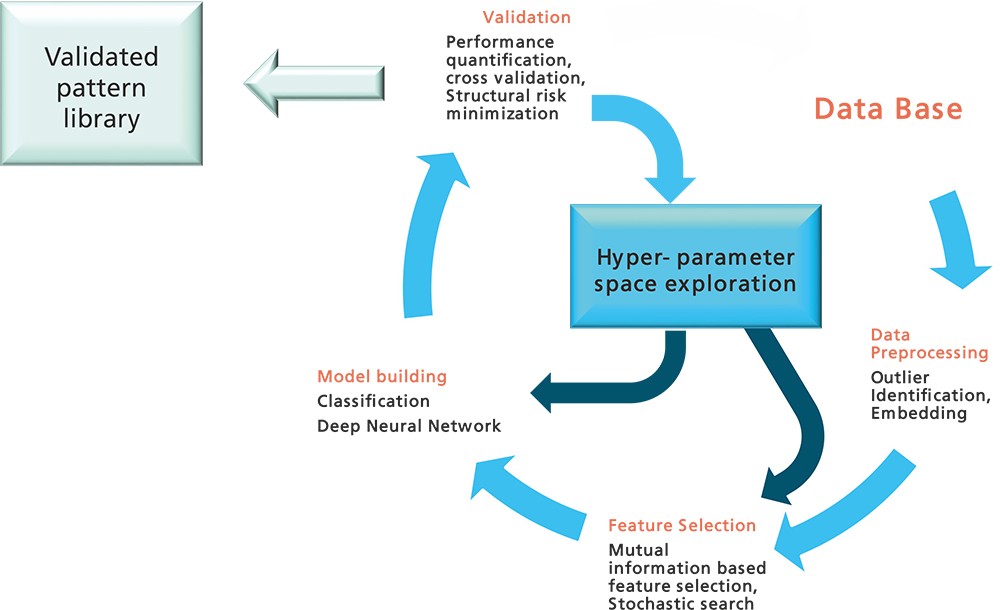
Entsprechende übergeordnete Methoden sind dann »Deep Belief Networks« und »Deep Neuronal Networks«. Der Lernalgorithmus für die RBM, »constructive divergence« (CD) genannt, erlaubt ähnlich wie beim stochastischen Gradientenabstieg ein inkrementelles Update von Batch zu Batch. Hierbei spielt die Wahl der so genannten Hyperparameter eine wesentliche Rolle. Hier nutzen wir »Sequential Model Based Global Optimization« mittels Gaußprozessen und je nach Anwendung mittels Monte Carlo Markov Chain (MCMC).
 Fraunhofer-Institut für Techno- und Wirtschaftsmathematik ITWM
Fraunhofer-Institut für Techno- und Wirtschaftsmathematik ITWM